Database and cluster essentials
Learn about the essentials of databases and clusters in Exasol SaaS.
Databases and clusters
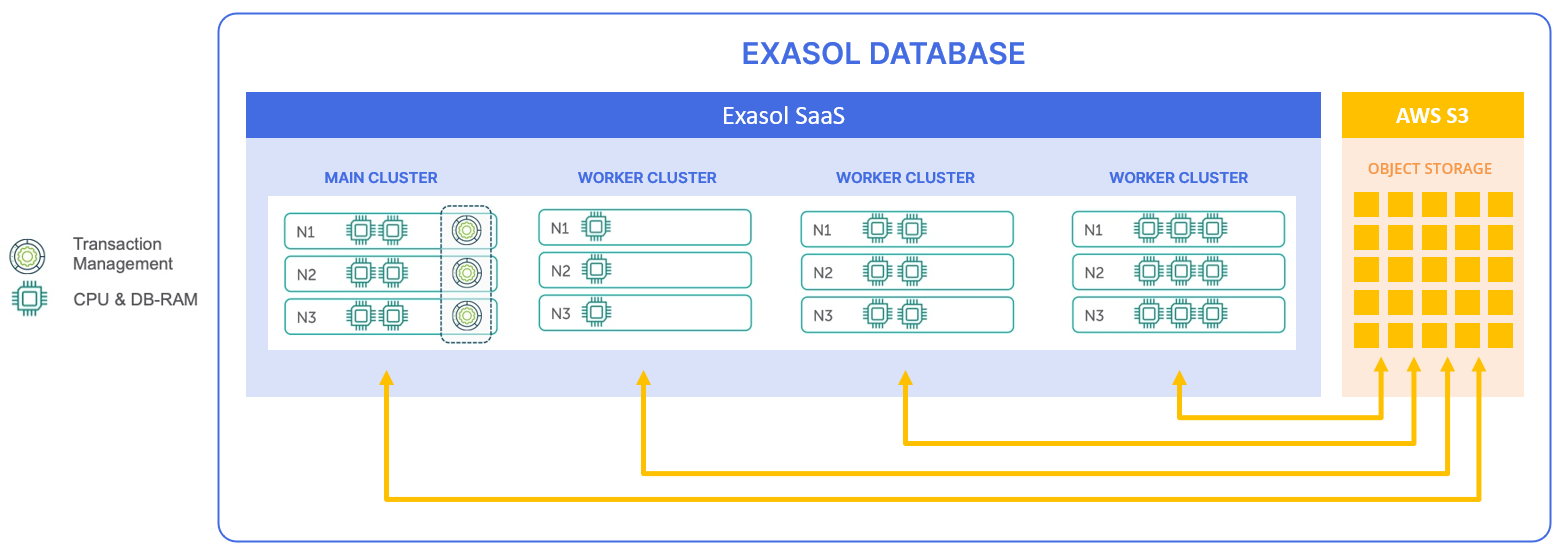
An Exasol database comprises one or more clusters. A cluster is a group of server nodes that handle all query operations in parallel.
The compute power of a cluster is based on the total number of CPUs and RAM. By using multiple clusters, it is possible to separate workloads between teams or tenants and allow for greater concurrency. Increasing the compute power in a cluster is referred to as vertical scaling. Adding more clusters is referred to as horizontal scaling.
The first cluster of a database is called the main cluster, while all other clusters are called worker clusters. The main cluster has a special role: it communicates with all worker clusters and ensures that they have a consistent view of transactions and metadata. Each cluster has a direct connection with the end users and with the central data store, and only metadata is transferred between the clusters.
Object storage
Data and metadata for the database are stored in a central data store such as an S3 bucket, not in the clusters. All clusters and nodes in a database access the same underlying data and metadata. Changes that are persisted from one cluster are persisted in the data store and are also persistent for all other transactions in the database, regardless of which cluster they are connected to.
Database scalability
The scalability of a database is the ability to increase and decrease resources based on business demands. Scalability can entail both vertical scaling (changing cluster resources) and horizontal scaling (changing the number of clusters).
Vertical scaling
Vertical scaling means changing the compute power and memory available for a database to optimize concurrency. When you scale up or down, the amount of VCPUs and RAM allocated to the cluster is adjusted based on the new cluster size. Use vertical scaling when you want to:
- Speed up the queries you are executing
- Run large complex queries or support bigger data sets without affecting performance
- Add more users or concurrency without affecting performance
The optimal cluster size for an Exasol database is determined based on usage patterns. As a rule of thumb, start with a RAM size that corresponds to about 10 percent of the size of your raw data.
Depending on your workload you may need a larger cluster size to use additional CPU and memory. However, a smaller cluster may also meet your requirements and be more cost effective. You can dynamically test which size best fits your needs by resizing the cluster.
Example:
A business has one database with a single cluster. As the data and the number of users on the system grows, users start to experience performance issues while working on the database. In this case, resizing the cluster to use a larger instance type would lead to a noticeable improvement of all queries.
For more information about how to vertically scale a cluster, see Resize cluster.
Horizontal scaling
Horizontal scaling means adding more clusters to the database. You can use horizontal scaling to optimize concurrency and manage higher workloads, and when you want to isolate different workloads.
Increased concurrency can be achieved both by horizontal and vertical scaling. If there are no separate workloads with separate groups of users, we recommend starting with vertical scaling. If this is no longer sufficient, or if there are different workloads, we recommend creating dedicated clusters.
Example:
A business can have the following two use cases to scale Exasol horizontally:
- A team of business intelligence analysts uses Exasol through a BI tool and SQL clients. Automated reports or interactive queries are running 24/7. Almost all data is accessible, except the clickstream table.
- The data science team wants to analyze large data sets (clickstream table), which require a very large cluster with high memory and CPU resources to ensure fast processing of the queries. However, the team does not need the cluster all the time.
Having two separate clusters for BI and data science will in this case be beneficial for the following reasons:
- The clusters will always have the relevant data in RAM, leading to optimal performance.
- You can scale the clusters independently as needed for the individual workload.
- The compute resources are isolated, which means that work done by the data science team will not affect the performance of the BI workload.
- The cluster for the data science team can be stopped when not required to save cost.
For more information about how to add and manage clusters, see Add cluster and Start and stop clusters.