Get started with Lakehouse Turbo in Exasol SaaS
Learn how to sign up and get started using Lakehouse Turbo in Exasol SaaS.
This article describes Lakehouse Turbo in Exasol Saas. To learn how to use Lakehouse Turbo in an as-application deployment of Exasol, see Lakehouse Turbo.
Introduction
You can sign up for a free trial of Lakehouse Turbo to explore the full power of the plug-and-play query engine without cost. The trial account provides all the functionality of Exasol SaaS for a limited time. After the trial period ends, you will be charged monthly for the subscription.
This article describes how to sign up and get started with the Lakehouse Turbo trial. You can also enable Lakehouse Turbo for a new database in an existing Exasol SaaS account. In that case, skip the first step and go directly to Add a database.
Prerequisites
Using Databricks
-
An active Databricks account with external data access enabled for the metastore
If external access is not enabled in Databricks (for vended credentials), you also need:
-
Access to the AWS or Azure account that hosts the data lakehouse
-
Adequate permissions on the storage account to grant Lakehouse Turbo access to the data
Using Apache Iceberg
For more information, see Lakehouse Turbo with Apache Iceberg.
-
The Iceberg catalog must be reachable from Exasol SaaS.
Sign up
Sign up for a free trial account on https://cloud.exasol.com/lakehouse-turbo-signup. You will receive a verification email with instructions on how to set up your account and create a secure password. After setting up your account, you will receive another email with your account details and can sign in.
Add a database
The first time you sign in, you will be asked to add a new database. If you are already signed in to Exasol SaaS, you can add a new database from the Databases page.
-
Select the AWS region where the Exasol database should be deployed.
To avoid cross-region data transfer costs when using Amazon S3 storage, select the AWS region where the S3 bucket that contains your data lakehouse is deployed.
-
Enter a name for the database.
-
Select Innovation Release as the release stream. Lakehouse Turbo is not supported in the Feature and Enterprise release streams.
-
Choose a cluster size based on the amount of data to be mirrored in Lakehouse Turbo.
-
Select a timeout value for the Cluster auto-stop feature, which automatically stops the cluster after a period of inactivity. The default value is 120 minutes. You can also disable the auto-stop feature.
Disabling the auto-stop feature may result in increased cloud resource usage.
Example:
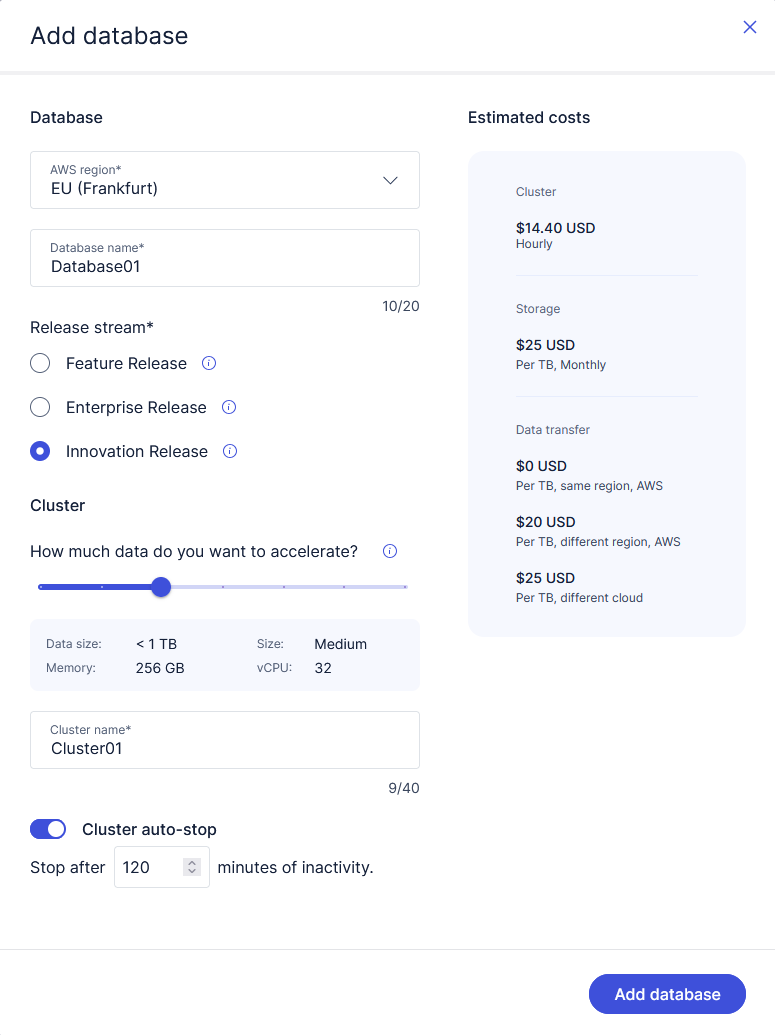
When you have finished setting the options for your database, click on Add database.
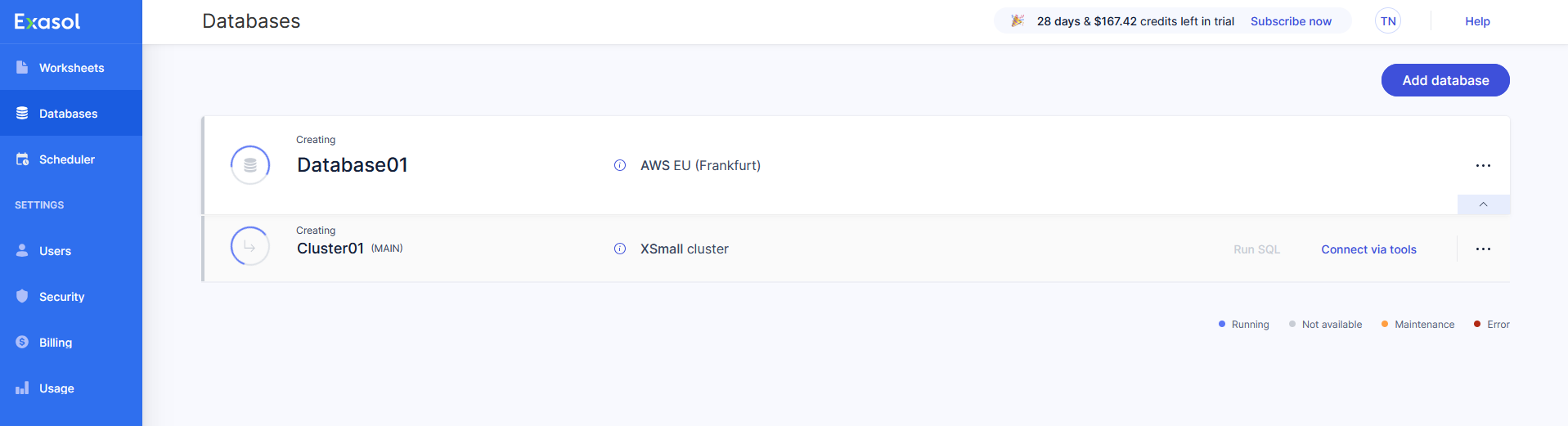
On the Databases page, the new database and cluster will have the status Creating until they are ready for use. The creation process will take about 15 minutes to complete. You will receive an email when your database is ready for use.
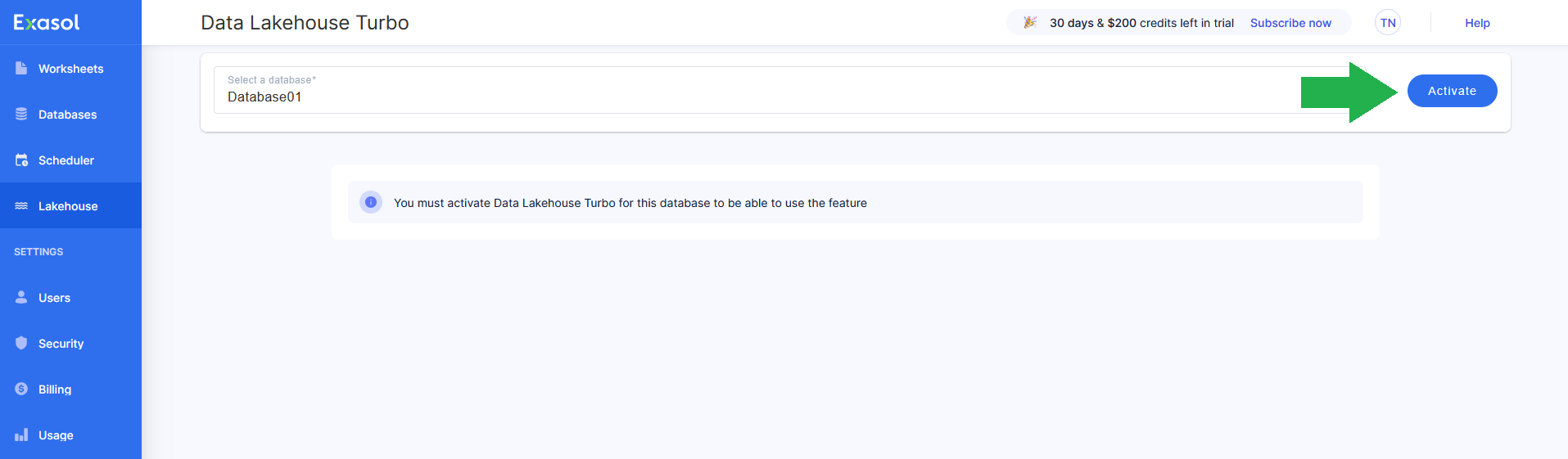
Activate Lakehouse Turbo
-
Log in to Exasol Admin and open the Lakehouse page.
-
Click on Activate to activate Lakehouse Turbo for the selected database.
Configure access
This section describes connecting to a Databricks catalog using the Lakehouse Turbo UI. To connect to Apache Iceberg catalogs you must change the default source system to Iceberg through the REST API. For more information, see Lakehouse Turbo REST API.
Screenshots and descriptions of the Databricks UI are for orientation only and may differ from the current version of Databricks. For up-to-date information, refer to the Databricks documentation.
To be able to mirror selected tables within Exasol, Lakehouse Turbo needs read access to the metadata (Catalog) and storage layer (Data Lake).
-
To grant access to the catalog in Databricks you can use a Databricks personal access token (PAT) or OAuth.
-
To grant access to the data lakehouse you can either use vended credentials (recommended) or use authentication provided by the storage provider (AWS or Azure).
Catalog access (Databricks PAT)
-
In your Databricks account, go to Settings > Access tokens > Manage > Generate new Token to generate a new personal access token.
Select the scope unity-catalog for the token, enter a descriptive comment (name) and a and click on Generate.

Copy the token from the dialog window.

Make sure to copy the token since it is only shown once and cannot be retrieved later.
For more help, see Create personal access tokens for workspace users in the Databricks documentation.
-
In
-
In Catalog > Host, enter the URL of the Databricks workspace host.
-
Disable OAuth if it is enabled.
-
In Catalog > Token, enter the Databricks personal access token.

-
Click on Save to save the settings.
Catalog access (OAuth)
To use OAuth with Databricks, you must create an OAuth service principal in the Databricks account and grant it read access to Databricks REST API.
For information about using OAuth with Iceberg catalogs, refer to the catalog provider's documentation.
-
Create an OAuth Principal in your Databricks account
In Databricks you can add service principals either on the account level or on the workspace level. To add and configure a service principal on the account level you must have the account admin role. See the following sections in the Databricks documentation:
-
Assign the OAuth service principal to your Databricks workspace
The next step is to assign the OAuth service principal to your Databricks workspace. You can do this using either the account console or the workspace admin settings page. See the following sections in the Databricks documentation:
-
Grant the following privileges to the service principal on the catalogs, schemas, or tables that should be mirrored by Lakehouse Turbo:
-
USE SCHEMA(prerequisite) -
EXECUTE(read) -
READ VOLUME(read) -
SELECT(read)
-
-
Generate a secret to enable authentication for the service principal.
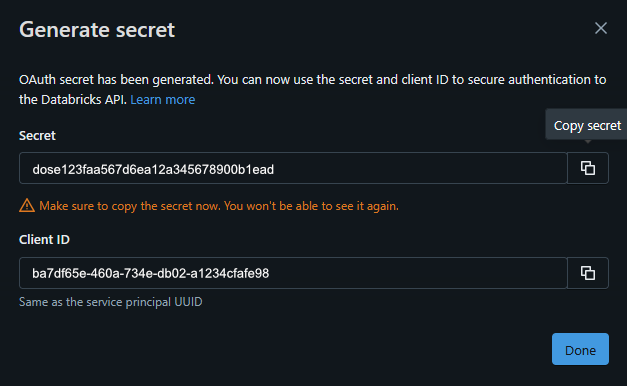
Make sure to copy the secret since it is only shown once and cannot be retrieved later.
-
In
-
Enable OAuth and enter the Client ID and Secret that you generated for the OAuth service principal.

-
Click on Save to save the settings.
Data lake access (Vended)
If you choose to use vended credentials, Databricks provides temporary table credentials to access both the catalog metadata and the underlying storage. External data access must be enabled in the Databricks metastore, and the user must have the EXTERNAL USE SCHEMA privilege on the schema or its parent catalog. No further configuration is needed in Lakehouse Turbo.
If external data access is not be available in your Databricks account, contact your Databricks account administrator.
For information about using vended credentials with Iceberg catalogs, refer to the catalog provider's documentation.
-
In the Databricks workspace, enable External data access for the metastore.

-
Grant the
EXTERNAL USE SCHEMAprivilege on the catalog or schema to the principal (user):Copy-- grant access to a schema
GRANT EXTERNAL USE SCHEMA ON SCHEMA <catalog_name>.<schema_name> TO `my_user@example.com`
-- grant access to a whole catalog
GRANT EXTERNAL USE SCHEMA ON CATALOG <catalog_name> TO `my_user@example.com`For more help, see Enable external data access to Unity Catalog in the Databricks documentation.
-
In
-
In Data Lake > Credential, select Vended.
-
Click on Save to save the settings.

Data lake access (Azure)
-
In
-
In Data Lake > Credential, select Azure.
-
In Azure Account Key, provide your Azure storage account access key.

Data lake access (AWS)
Step 1: Get prerequisites
-
In
-
In Data Lake > Credential, select AWS.
-
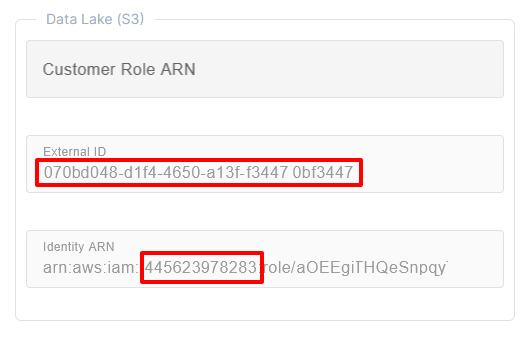
Copy the contents of the External ID field and the the 12-digit AWS Account ID from the Identity ARN field.
Example:
Step 2: Create a new IAM role in AWS
-
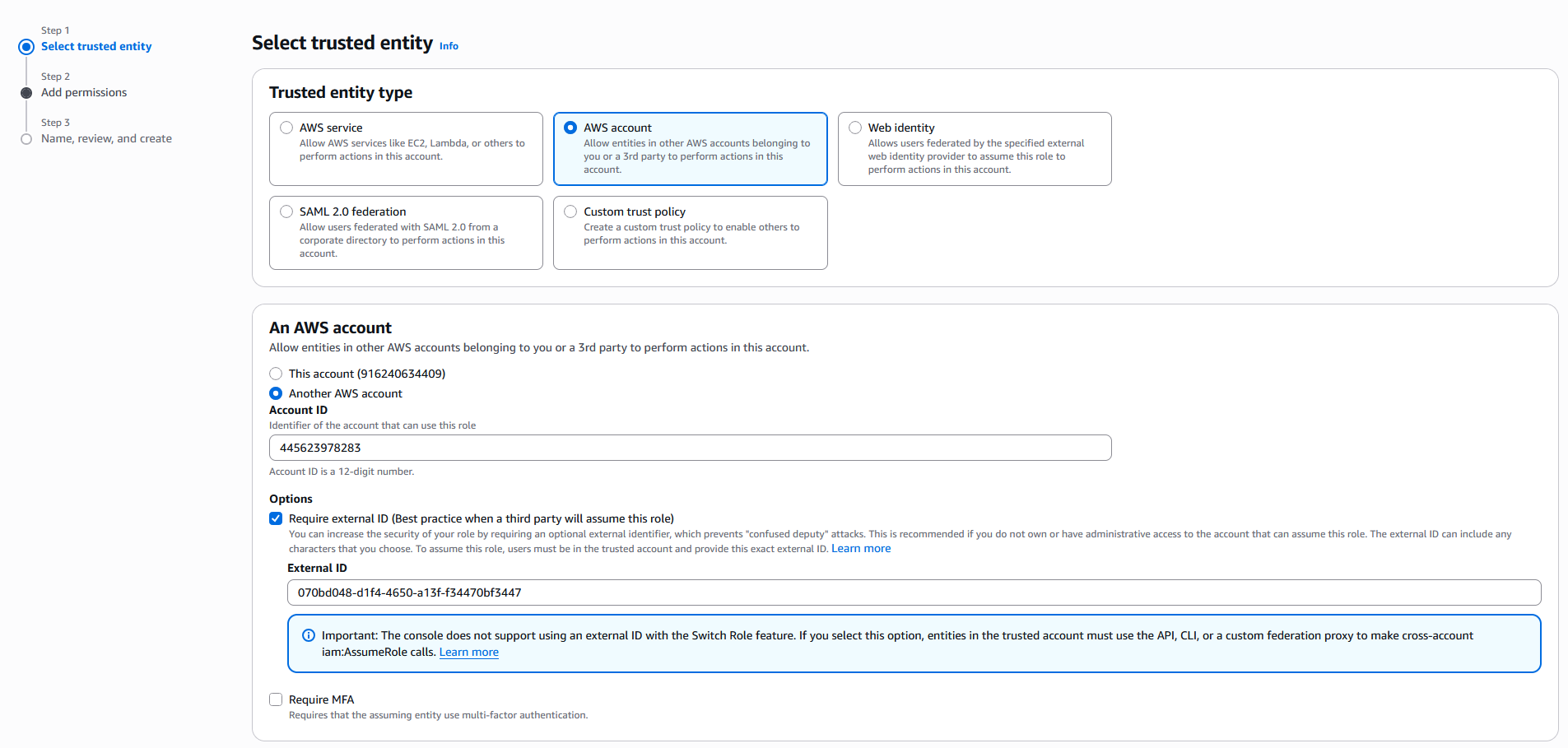
In the AWS account that hosts the S3 bucket of the data lakehouse, navigate to IAM and create a new role with the following settings:
-
Trusted entity type = AWS Account
-
Another AWS Account -> Account ID = AWS Account ID copied from the Lakehouse Turbo Settings tab (see previous step)
-
External ID = External ID copied from the Lakehouse Turbo Settings tab
Example:
-
-
Add the permission policy
AmazonS3ReadOnlyAccess
. If desired, set a permissions boundary to limit access to the S3 bucket.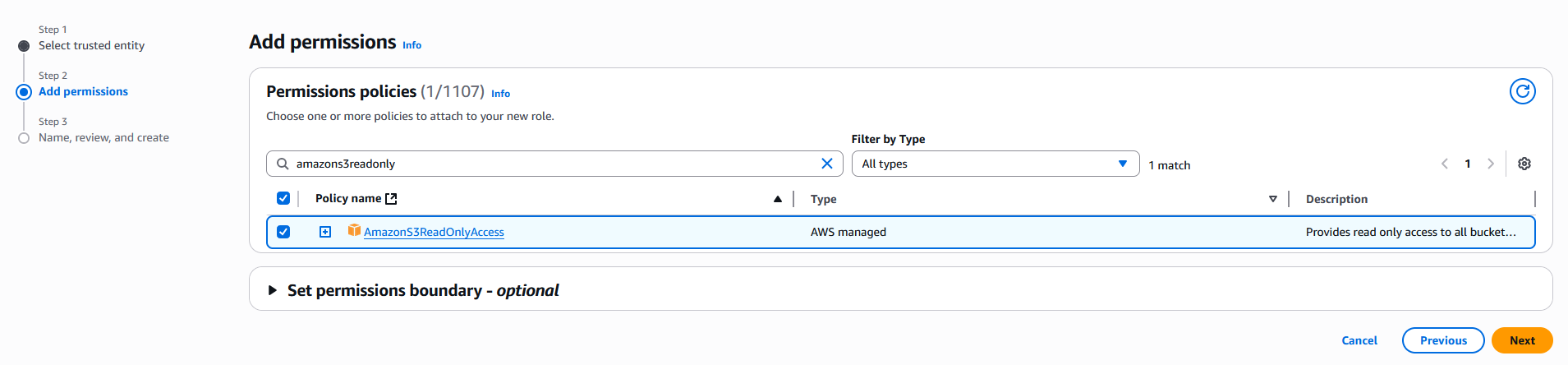
-
Click on Next, review the settings and add a name and description for the role, then click on Create role.
For more help with configuring IAM roles, see the AWS IAM documentation.
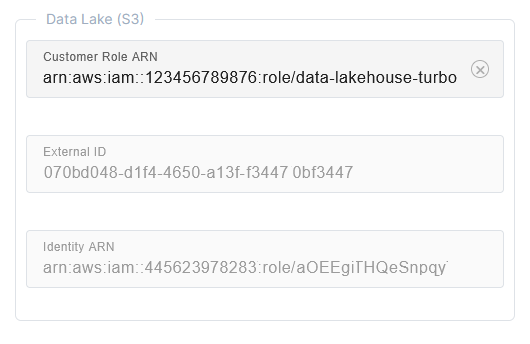
Step 3: Add the Customer Role ARN in Lakehouse Turbo
In the Lakehouse TurboSettings tab, enter the ARN of the newly created role in the Customer Role ARN field in the Data Lake (S3) section.
Example:
Optional - Grant access to the role within S3
This step is only required if the created IAM role is in a different AWS account than the S3 bucket.
In the AWS account that hosts the S3 bucket of the data lakehouse, navigate to S3 and do the following:
-
Locate the S3 bucket of your datalake
-
Click on the bucket name and navigate to the Permissions tab
-
Create the role and copy the ARN of the role
-
Add the following statement to the Bucket policy:
Copy{
"Sid": "Grant access for Data Lakehouse Turbo",
"Effect": "Allow",
"Principal": {
"AWS": "${ROLE_ARN}"
},
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"${BUCKET_ARN}/*",
"${BUCKET_ARN}"
]
}
Next steps
Once you have connected to your data lakehouse, the next step is to select the catalog and schemas that you want to accelerate using the smart caching in Lakehouse Turbo.