Learn about best practices for optimizing performance in Exasol.
Appropriate data types
- Choosing appropriate data types is a key factor during data modeling. It provides a good compression and avoids unnecessary type conversions or expression indexes.
- Keep formats short. For example, do not use
VARCHAR(2000000)orDECIMAL(32,X)if a smaller range is sufficient. -
Prefer exact data types.
- Prefer
DECIMALoverDOUBLEif possible. Double has a wider scale but is less efficient. - Prefer
CHAR(x)overVARCHAR(x)if the length of the strings is a known constant (CHARis fixed size). - Use identical types for same content: Avoid joining columns of different data types. For example, do not join an
INTcolumn with aVARCHARcolumn containing digits. - To learn more about optimizing data types, see Post load optimizations .
Replication
To increase the speed of queries, the Exasol query optimizer replicates "small tables" of a query so that global joins become fast local joins. During query execution, all needed data from “small tables” are replicated in local DB RAM and data from all nodes is accessed locally. No communication is needed and access is very fast. Since the data resides in DB RAM, multiple queries that need the same data can share the replicated data.
The replication border sets the upper size limit for a "small table" that the query optimizer will consider replicating. The default replication border is 100,000 rows. This border can be increased. For example, if you have a star schema, consider increasing the replication border so that all your dimension tables are replicated.
REPLICATION_BORDER = <unsigned_integer>. The following example sets the replication border to one million rows for a TPC-H benchmark:
ALTER SYSTEM SET REPLICATION_BORDER = 1000000;The query optimizer may not replicate all tables that fit within the replication border. For example, modified tables that are not committed will not be considered by the query optimizer for replication even when the tables fit within the replication border.
Distribution keys
Distribution key scenarios
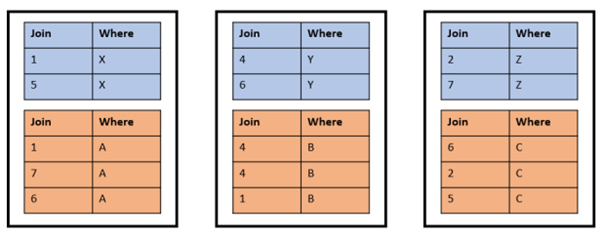
Any table whose size exceeds the replication border (large tables) is distributed on a row-by-row basis across all active nodes. Without specifying a distribution key, the distribution is random and uniform across all nodes. Setting a proper distribution key on join columns of the same data type converts global joins to local joins and improves performance. Take the following two tables as an example:
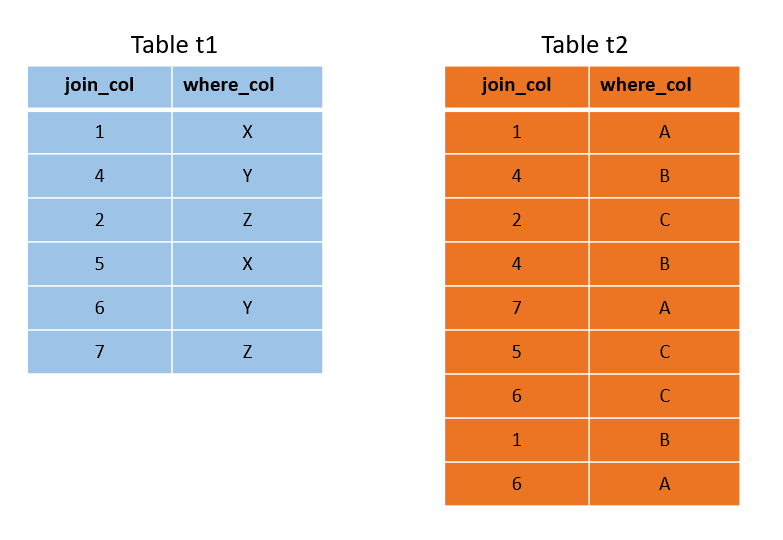
The tables are joined on the join_col and filtered on the where_col. Other columns are not displayed to keep the sketch small. Small tables like these are normally replicated, but for this example, we ignore that. A random distribution on a three node cluster may look like this:
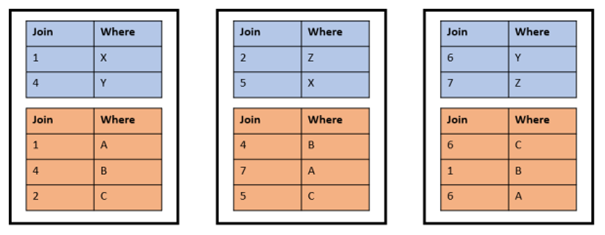
If the tables are now joined on the join_col with the following statement, the random distribution is not optimal:
SELECT * FROM t1 JOIN t2 ON t1.join_col = t2.join_col;
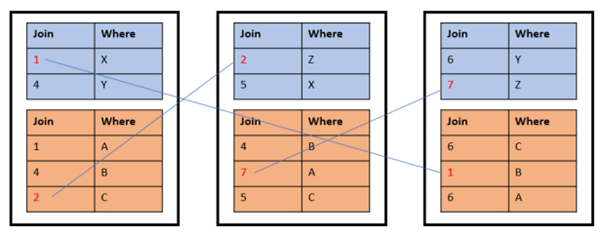
This is processed as a global join internally. It requires network communication between the nodes on behalf of the join because the highlighted rows don't find local join partners on the same node.
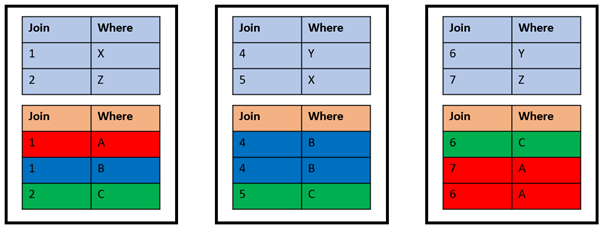
You can change the distribution of both tables using the following statements, allowing the system to recognize a match between join column and table distribution.
ALTER TABLE t1 DISTRIBUTE BY join_col;ALTER TABLE t2 DISTRIBUTE BY join_col;You can only set one distribution key per table.
Then the same query is processed internally as a local join:
Every row finds a local join partner on the same node, so the network communication between the nodes on behalf of the join is not required. The performance with this local join is better than with the global join although it’s the same SELECT statement.
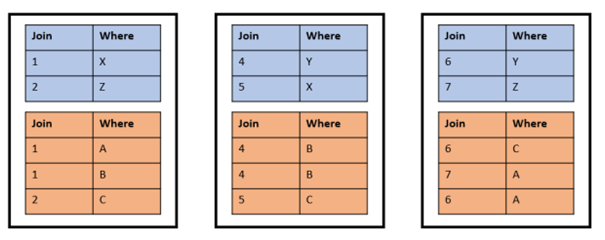
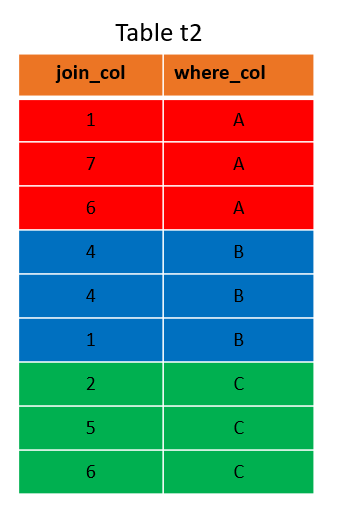
It’s a good idea to distribute on JOIN columns. However, it’s not good if you want to distribute columns that you use for filtering with WHERE conditions. If you distribute both tables on the where_col columns, the result will look like this:
This distribution is worse than the initial random distribution. This causes global joins between the two tables and statements like <Any DQL or DML> WHERE t2.where_col='A'; utilize only one node (the first with this WHERE condition). This disables Exasol’s Massive Parallel Processing (MPP) functionality. This distribution leads to poor performance because all other nodes in the cluster are on standby while one node does all the work.
Exasol's resource management assumes uniform load across all nodes. Therefore, this distribution leads to resources being unused even when multiple simultaneous statements operate on different filter values (for example, nodes). The MPP relies on a near-uniform distribution of data across the nodes, so columns where few values dominate the table are usually bad candidates for distribution. Distributing by a combination of columns (see Distribution on multiple columns) may alleviate this problem.
Distribution on multiple columns
The ALTER TABLE (Distribution/Partitioning) statement allows distribution over multiple columns in a table. However, to take advantage of this, all those columns must be present in a join. Therefore, for most scenarios, distributing by a single column is appropriate. The requirement for a local join is that the distribution columns for both tables must be a subset of the columns involved in the join. Let's look at the following example. Imagine you have two tables defined with the following DDL:
CREATE TABLE T1 (
X INT,
Y INT,
Z INT,
DISTRIBUTE BY X
);
CREATE TABLE T2 (
X INT,
Y INT,
Z INT,
DISTRIBUTE BY X
);Since these tables are both distributed by the column X, join conditions which include (but are not limited to) these columns will be local. This includes the following queries:
SELECT * FROM T1
JOIN T2 ON T1.X = T2.X;
SELECT * FROM T1
JOIN T2 ON T1.X = T2.X
AND T1.Y = T2.Y;
SELECT * FROM T1
JOIN T2 ON T1.X = T2.X
AND T1.Y = T2.Y
AND T1.Z = T2.Z;Since the distribution keys (T1.X and T2.X) are included in each of the joins, the entire join is operated locally. Changing the distribution key to cover multiple columns will have a negative impact in this case. For example, let's distribute the tables now by columns X and Y:
ALTER TABLE T1 DISTRIBUTE BY X,Y;
ALTER TABLE T2 DISTRIBUTE BY X,Y;Now, only the second and third examples will have local joins. A simple join on T1.X = T2.X will be a global join because the distribution keys are no longer a subset of the join conditions.
Check how a new distribution key distributes rows
Let's consider a scenario where you plan to change the distribution key to use column aa_00 and you want to see how it is going to distribute rows. This is a type of check that allows you to see the distribution before you implement the distribution key.
Run the following statement to check the distribution of the new distribution key.
SELECT value2proc(aa_000) as Node_Number, round(count(*) / sum(count(*)) over() * 100 ,2) as Percentage
from <table name>
group by 1;If the distribution is very uneven or skewed, it is not recommended to implement the new distribution key.
Conclusion:
- Do: Distribute on
JOINcolumns to improve performance by converting global joins to local joins. - Do: Pick the smallest viable set of columns that will be part of all your most frequent or expensive joins as distribution key.
- Don't: Distribute on
WHEREcolumns, which leads to global joins and disables the MPP functionality, both causing poor performance. - Don't: Add unneeded columns to a distribution key.
Avoid ORDER BY in views
Views are often treated as tables by end users, who are not aware that an ORDER BY clause is part of the view’s query. The ORDER BY clause in the view is then superfluous and slows down view performance. Similarly, ORDER BY clauses in sub-queries will slow down query performance and cause materialization, which may not be required. There should be only one ORDER BY clause (if any) at the end of an SQL statement.
In some cases, using an ORDER BY FALSE statement to materialize a sub-select may actually improve performance. For more information, see Enforcing Materializations with ORDER BY FALSE.
Manual index creation
Exasol automatically creates and maintains indexes as needed. We recommend that you do not manually create indexes, as this will interfere with the automatic process and could result in unexpected behavior and performance issues. For more information about how indexes work, see Indexes.
Use surrogate keys
Joins on VARCHAR and DATE/TIMESTAMP columns are expensive compared to joins on DECIMAL columns. Joins on multiple columns generate multi-column indexes, which require more space and effort to maintain internally compared to single column indexes. To avoid these problems, use surrogate keys instead.
Favor UNION ALL
The difference between UNION and UNION ALL is that UNION eliminates duplicates, thereby sorting the two sets. This means that UNION is more expensive than UNION ALL. In cases where it is known that no duplicates can occur or when duplicates are acceptable, use UNION ALL instead of UNION.
Partitioning
If the tables in your database are too large or too numerous to fit completely into the node’s memory, partitioning large tables can help improve performance. Take these two tables as example:
Say t2 is too large to fit in memory and may get partitioned therefore.
In contrast to distribution, partitioning should be done on columns that are used for filtering:
ALTER TABLE t2 PARTITION BY where_col;Now without taking distribution into account (on a one-node cluster), the table t2 looks like this:
Partitioning changes the way the table is physically stored on disk. It may take much time to complete such an ALTER TABLE (Distribution/Partitioning) command with large tables.
A statement like SELECT * FROM t2 WHERE where_col=’A’; would have to load only the red part of the table into memory. Should the two tables reside on a three-node cluster with distribution on the join_col columns and the table t2 partitioned on the where_col column, they look like this:
Again, this means that each node has to load a smaller portion of the table into memory if statements are executed that filter on the where_col column while joins on the join_col column are still local joins.
EXA_(USER|ALL|DBA)_TABLES (see Metadata system tables) shows both the distribution key and the partition key if any.
Exasol will automatically create an appropriate number of partitions.
Database monitoring
The tables in the Statistical system tables schema can be used to monitor the health of the database. They come with detailed values for the last 24 hours and aggregated values on an hourly, daily and monthly basis: EXA_DB_SIZE*, EXA_MONITOR*, EXA_SQL* and EXA_USAGE*. Other important tables to monitor are EXA_DBA_TRANSACTION_CONFLICTS and EXA_SYSTEM_EVENTS. The meta view EXA_SYSCAT lists all these tables together with a description.
CPU utilization
A high CPU utilization is normal for a healthy system. Low CPU utilization (on a busy system) is an indicator that a bottleneck exists somewhere else. CPU_MAX from EXA_MONITOR_DAILY should be normally above 85% therefore.
TEMP utilization
Analytical queries often consume a lot of memory for sort operations. The EXA_MONITOR* tables should be monitored to confirm that the total TEMP memory consumption is below 20% of the total available database RAM, while the EXA_SQL* and EXA_*_SESSIONS tables should be monitored to confirm that a single query doesn’t consume more than 10% of available database memory.
DB RAM recommendation
Exasol performs well with parallel in-memory processing analytical queries. This requires that sufficient memory is available. The EXA_DB_SIZE* tables have RECOMMENDED_DB_RAM_SIZE where the system reports if it would be beneficial to increase DB RAM of the cluster. This may require adding more RAM to the data nodes..
Avoid the USING syntax
The use of the USING syntax in queries containing multiple joins leads to an inefficient execution and high amount of heap memory usage by the SQL processes.
Example:
SELECT * FROM T1 JOIN T2 USING (id) JOIN T3 USING (id) JOIN ...In the above example, USING(id) is not just syntactic sugar for ON T1.id = T2.id.
The database has to decide the values for the columns that appear in both the tables. For example, when T1.name has a NULL value, and T2.name is different from NULL, then the value of the output column name will be T2.name. This effort increases exponentially on the number of joins.
Instead, you can use the following statement for a better performance.
SELECT * FROM T1 JOIN T2 ON T1.id=T2.id JOIN T3 ON T2.id=T3.id JOIN ...Storage capacity and disk exhaustion
Exasol requires sufficient available storage capacity for normal database operation, maintenance activities, temporary workloads, and recovery processes. If available storage is exhausted, the system may reject write operations, fail ongoing operations, or restrict database functionality in order to protect data integrity and maintain a consistent database state. Under such conditions, uninterrupted database operation is not guaranteed. If needed to protect your data, the database will initiate an emergency shutdown.
Exasol is designed to prioritize data consistency over availability, and storage exhaustion conditions are not expected to result in data corruption. Once sufficient storage capacity has been restored, normal database operation and recovery procedures can be resumed in accordance with documented recovery processes.
As a user you must plan resource capacity and monitor usage to ensure that the database can operate with optimum performance and to prevent failures. We recommend that you configure alerts to notify administrators before storage capacity becomes critically low.
Exasol offers monitoring services as a part of our Platinum support. For more information, see Support or contact us.
Recommended limits for disk space usage
| Disk space usage | Recommended action |
|---|---|
|
≥ 75%: |
Monitor the usage to detect a trend. If you see a linear growth in disk space usage, start planning disk expansions. |
| ≥ 85% |
Warning – Start planning for increasing your disk capacity. |
| ≥ 90% |
Critical – Free up disk space or enlarge your storage as soon as possible. |
Critical storage threshold (90% or above)
Database operations such as index creation, query processing, maintenance activities, data loading, and temporary data handling require additional free disk space beyond the currently stored data volume. As available storage becomes constrained, workloads that rely on temporary disk space may experience increased execution times, reduced throughput, or operation failures.
Maintaining at least 10% free storage capacity helps ensure that sufficient space remains available for workloads that rely on temporary disk space. Operating above 90% utilization increases the risk of performance degradation, failed operations, and restricted database functionality.
For this reason, we strongly recommend that you treat storage utilization exceeding 90% as a critical condition and investigate and remediate it without delay.