Sizing guidelines
Learn how to determine the disk space and RAM that will be required for your Exasol database.
Factors that impact sizing
There are several factors that determine the storage disk space and RAM that will be required for an Exasol system. The major factors to consider are:
-
The expected volume of your raw data
-
The volume of your uncompressed (raw) data has the largest impact on the estimation of the required storage disk space. The larger the data volume, the more storage space is required. Table data in an Exasol database is automatically compressed to optimize disk space usage.
-
Performance
-
The amount of RAM that is allocated for the database (DB RAM) will have a direct impact on performance. When estimating how much DB RAM you need, you can use the rule-of-thumb of 10% of the volume of your uncompressed data. For a more precise value you can calculate the amount of active data, or use the actual values in Exasol system tables.
-
Cluster redundancy
-
The planned redundancy for the cluster affects the required storage space. With redundancy
2
– meaning that the same data is stored in two segments – the required storage space is effectively doubled. -
Number of reserve nodes
-
Reserve nodes are used in case of a node failure. A reserve node must have the same hardware configuration as the active nodes in a cluster. For more information, see Fail safety (cloud)
-
Backup strategy
-
Certain backup strategies require more storage space. If you plan on storing backups in the cluster (local backups) with redundancy
2
, then this must be taken into account when estimating disk size. For more information, see Backup and restore. -
Operating system reserved RAM
-
We recommend that you reserve 10% RAM for the operating system on each node. This must be considered when calculating the amount of RAM to allocate for the database (DB RAM).
Database disk space
The total required disk space for an Exasol system is the sum of the required database disk space and the required backup disk space. The factors that you should consider when calculating the database disk space are:
-
Compressed data volume
-
Table data in an Exasol database is automatically compressed. A typical compression rate is ~2.5, which means that if the raw data volume is 2500 GiB, the estimated compressed data volume is ~1000 GiB.
-
Index volume
-
Indexes are automatically created and maintained by the database and require disk space. The index size depends on the chosen data model and queries, and can range from 2% to over 100% of the compressed data. A typical Exasol system will have an index volume of about 15% of compressed data.
-
Statistical and auditing data volume
-
Statistical data volume is small. However, if you switch auditing on in the system, the required disk space increases because each login and each query is stored in the corresponding auditing tables.
-
Temporary data and fragmentation
-
When intermediate results do not fit into the database RAM they are swapped out to a temporary volume. We recommend that you reserve extra headroom for temporary DB RAM.
-
The persistent volume can become fragmented to some degree, which increases the amount of disk space taken up by the data. We recommend that you reserve additional disk space to avoid running out of space due to fragmentation.
-
As a rule of thumb, add 60% of the compressed data volume (without redundancy) as combined additional headroom for temporary data and fragmentation.
Database disk space calculation
To calculate the required disk space for the database, use the following equation:
Compressed data volume + Index volume + Statistical and auditing data volume
* Redundancy
+ Temporary data and fragmentation headroom
= Required database disk space
Example:
In this example we have the following input parameters:
- Raw data volume: 2500 GiB
- Redundancy: 2
Using the above equation and rule-of-thumb guidelines, the calculation will be as follows:
| Parameter | Value | Explanation |
|---|---|---|
| Compressed data | 1000 GiB | 2500 GiB of raw data / 2.5 (average compression factor) |
| Index volume | 150 GiB | 15% of compressed data |
| Statistical and auditing data | 50 GiB | 5% of compressed data |
| Total data volume (net) | 1200 GiB | Compressed data + index volume + statistical and auditing data |
| Total data volume with redundancy | 2400 GiB | Total data volume (net) × 2 |
| Headroom for temporary data and fragmentation | 720 GiB | 60% of compressed data without redundancy |
| Required database disk space | 3200 GiB | Total data volume with redundancy + headroom for temp data and fragmentation |
Database RAM (DB RAM)
An Exasol database typically performs well with database RAM of 10% of the raw (uncompressed) data volume. However, several other factors also affect the required DB RAM:
-
Index volume
-
Indexes are automatically created and maintained by the database. The index size depends on the chosen data model and queries, and can range from 2% to over 100% of the compressed data. A typical Exasol system will have an index volume of about 15% of compressed data.
Higher index volumes can negatively impact system performance and require more DB RAM.
If you have a running system, you can get the actual size of the indexes from the
AUXILIARY_SIZE_*columns in theEXA_DB_SIZE_*statistical system tables. For more information, see Statistical system tables. -
Temporary data
-
When intermediate results do not fit into the available DB RAM they are swapped out to a temporary volume, which causes significant performance deterioration. Because of this, we recommend that you reserve extra headroom for temporary data (TEMP DB RAM).
-
User defined functions (UDFs)
-
When processing large amounts of data using UDFs, the RAM required for those UDFs must be available on every node. The UDFs are executed in parallel, which means that there can be as many instances of a UDF per node as there are cores. Therefore, you have to consider the total amount of RAM that the UDF instances need for processing the queries.
For example, if a query uses 500 MiB per UDF instance on a 72 core machine in an 8-node cluster, this requires an additional 282 GiB of DB RAM.
-
Additional software
-
Additional processes running on the nodes, such as monitoring services, may require that you reserve additional RAM headroom. In this case, refer to the respective software vendor’s documentation regarding RAM usage.
Database RAM calculation
To calculate the required DB RAM you can use the following equation:
MAX( COMPRESSED DATA VOLUME * ESTIMATED DB RAM PCT, INDEX VOLUME * INDEX SCALE FACTOR )
+ COMPRESSED DATA VOLUME * TEMP DB RAM HEADROOM PCT
+ MAX UDF RAM * NUMBER OF CORES * NUMBER OF NODES
= Required DB RAM
| Parameter | Explanation |
|---|---|
| COMPRESSED DATA VOLUME |
The compressed size of your raw data. Table data in an Exasol database is automatically compressed. A typical compression rate is ~2.5, which means that if the raw data volume is 2500 GiB, the estimated compressed data volume is ~1000 GiB. |
| ESTIMATED DB RAM PCT | An estimated percentage of the compressed data volume that will be needed for DB RAM. A typical value is 20%. |
| INDEX VOLUME |
The estimated size of indexes in the database. A typical Exasol system will have an index volume of about 15% of compressed data. |
| INDEX SCALE FACTOR |
A scale factor to allow for headroom for index volume. To ensure that index maintenance does not impact system performance, extra DB RAM should be considered for processing indexes. The index scale factor is multiplied by the estimated index volume and represents the minimum DB RAM required. The index factor is especially important if you expect to have a high index volume. |
| TEMP DB RAM HEADROOM PCT |
Additional DB RAM for processing temporary data, as a percentage of the compressed data volume. |
| MAX UDF RAM | The total amount of RAM that will be needed for your UDF instances. |
| NUMBER OF CORES | The number of cores in each node. |
| NUMBER OF NODES | The number of nodes in the cluster. |
If you have a running system, you can use the RECOMMENDED_DB_RAM_SIZE_* columns of the EXA_DB_SIZE_* statistical system tables to get a recommended DB RAM size. For more information, see Statistical system tables.
Example:
In this example we have the following input parameters:
| Raw (uncompressed) data volume | 2500 GiB |
| DB RAM size as % of compressed data volume | 20% |
| Index scale factor | 1.3 |
| Headroom for temporary DB RAM | 5% |
| Estimated UDF RAM requirement | None |
The resulting equation would then be:
MAX(1000 GiB * 20%, 150 GiB * 1.3) + 1000 GiB * 5% = 250 GiB
Explanation:
-
Required DB RAM based on the compressed data volume will be our starting point, since this is larger than the estimated index volume multiplied with the index scale factor (200 GiB vs. 150 GiB).
-
Additional headroom required for TEMP DB RAM is calculated to be 50 GiB (5% of 1000 GiB).
-
The total required DB RAM will thus be 200 GiB + 50 GiB = 250 GiB.
Amazon EC2 instance types
Amazon EC2 instance types are named according to the following convention:
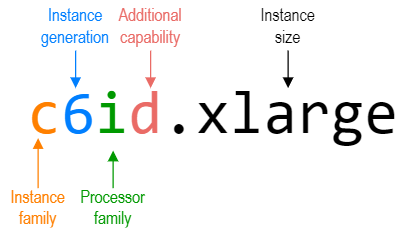
When you choose EC2 instance types for your Exasol deployments on AWS, use the following guidelines:
Instance family: Depending on your requirements, we recommend:
- c for workloads that require high CPU performance
- r for workloads that are data-heavy but compute-light
- m for a balance between CPU and memory optimization
Instance generation: Use the latest available generation for the selected instance type.
Processor family: Use only a (AMD) or i (Intel) processors. AWS Graviton (ARM) processors are not supported.
- Which processor architectures are available may differ depending on the instance generation.
- A certain processor family be implicit for some instance types.
Additional capability: Always specify d (instance store volumes).
Exasol will not work if the “d” option is omitted.
Instance size: Choose instance sizes based on Sizing guidelines and the total RAM that will be used by all your instances.
For more information about EC2 instance types, refer to Instance types - Amazon Elastic Compute Cloud.