Fail safety (cloud)
Learn about how fail safety works in cloud deployments of Exasol.
If the hardware component or server where a cluster node is running fails, Exasol detects that a node is no longer available and triggers an automatic failover procedure. If the volumes have been configured with redundancy, the metadata on each node is replicated to mirrors on neighboring nodes, which means that data integrity is preserved on node failure.
In case of node failure in a cloud deployment, Exasol will automatically shut down the affected databases, then try to restart the failed node and restore database connectivity. If the failed node cannot be restarted, two slightly different standby failover mechanisms are available for cloud deployments: cold standby and hot standby.
- Cold Standby
-
With this mechanism you have one or more inactive reserve nodes for the active nodes in your system. In case of a failure, the reserve node will start up and take over for the failed node. Cold standby is slower but more cost-effective than hot standby, since it does not require any additional active nodes.
Cold standby is implemented using the Exasol cloud failover plug-in, which comes pre-installed with all Exasol cloud offerings.
-
With this mechanism you have one or more active reserve nodes in the cluster. In case of node failure, the reserve node immediately takes over for the failed node and data is copied to this node from the mirrors. Hot standby is a relatively fast failover mechanism, but it is expensive since it requires additional active nodes.
Hot standby is available for cloud deployments and on premises installations of Exasol.
Cold Standby
The cold standby mechanism is designed specifically for deployment of Exasol on a cloud platform. This is a relatively slower but more cost effective mechanism for failover compared to the hot standby mechanism.
Prerequisites
- The cluster must include at least one standby node in suspended mode.
- The smallest supported cluster configuration is 3 active nodes + 1 standby node (3+1), because cold standby requires that more than 50% of the active data nodes are available during an outage.
Reserve nodes added by the cloud failover plug-in will be hot standby (active) nodes by default. To configure the reserve node as a cold standby node, you must shut down the node by stopping the resources from your cloud provider (AWS, Azure, or Google Cloud). For details of how to do this, refer to the documentation for the respective cloud platform.
What happens on node failure
A node failure triggers the following automatic sequence of actions:
- All affected databases on the cluster are stopped.
- The cloud failover plug-in restarts the system and tries to bring it back online.
- If the system does not come online, the reserve node is started.
- Database connectivity is restored.
- A background restore of data segments from mirrors to the new active node is started.
Hot Standby
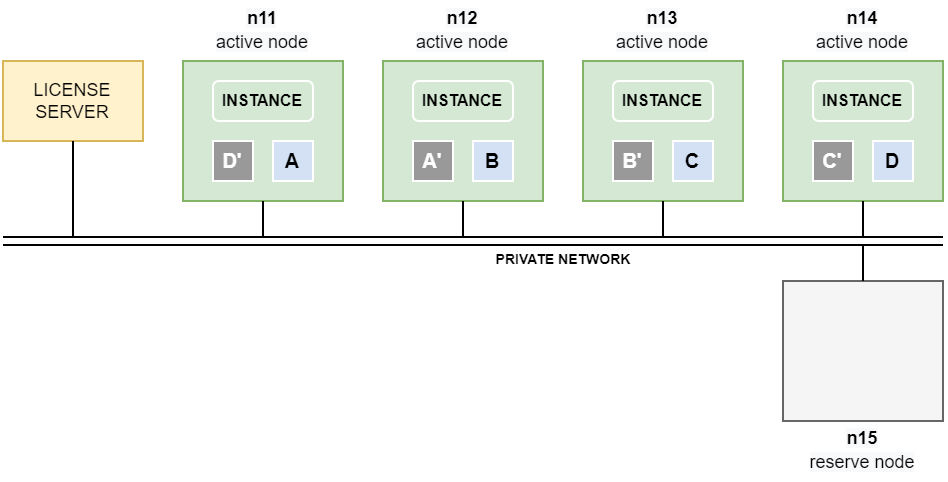
Example: 4+1 cluster with redundancy level 2
The following example shows an Exasol cluster with 4 active data nodes and one reserve node.
The volumes are configured with redundancy level 2, which means that each node contains a mirror of the data segments that are operated on by a neighbor node. For example, if node n11 modifies A, the mirror A‘ on the neighbor node n12 is synchronized over the private network.
What happens on node failure
A node failure triggers the following automatic sequence of actions by
- The node failure is detected.
- All affected databases on the cluster are stopped.
- The reserve node is activated and the failed node becomes a reserve node for the affected databases.
- All databases are restarted.
- Database connectivity is restored.
What happens next depends on whether the failed node comes back online within a specific timeout period (transient node failure) or if it does not come back (persistent node failure). In case of a transient node failure, a complete restore of data segments from mirrors to the new active node will not be required.
Persistent node failure
If the failed node n12 does not become available again before the
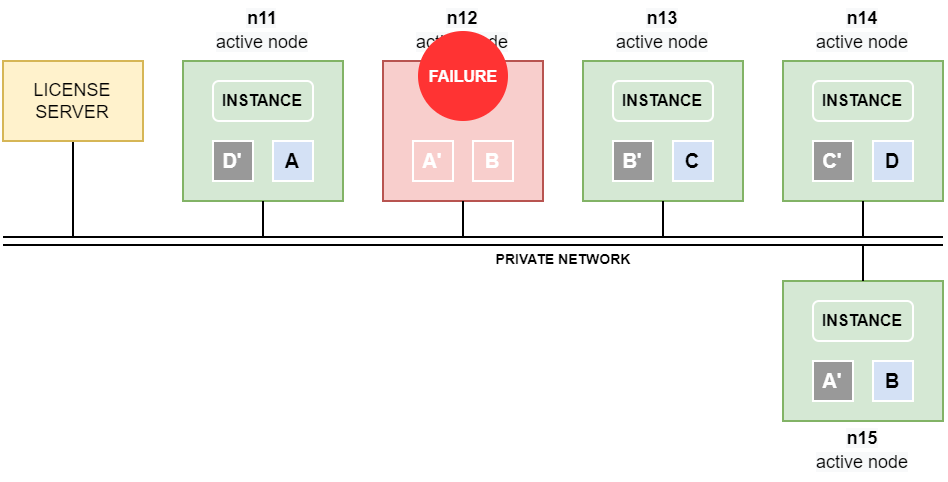
Data is automatically copied between the nodes over the private network. If the private network has been separated into a database network and a storage network, data is copied over the storage network.
Copying data between nodes is time consuming and can put a significant load on the private network.
In case of a persistent node failure we recommend that you add a new reserve node to replace the failed node.
Transient node failure
If the failed node n12 comes back before the timeout threshold is reached a complete restore of the mirrors towards node n15 is not necessary, and segments will therefore not be copied between the nodes. The segments A’ and B on node n12 are however now stale, since their mirrors on nodes n11 and n13 have been operated on in the meantime. The segments therefore have to be re-synchronized before they can be used again.
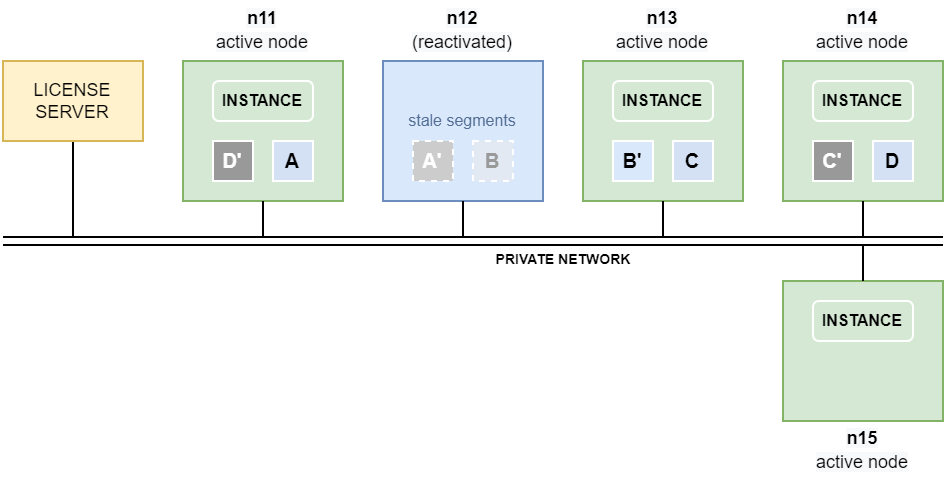
Fast mirror re-sync
As soon as node n12 is back online, the stale segments are automatically re-synced by the cluster operating system, applying the changes on A and B‘ that were done on their respective mirrors while n12 was offline. This activity is much faster and less load-intensive than a complete restore of segments towards node n15.
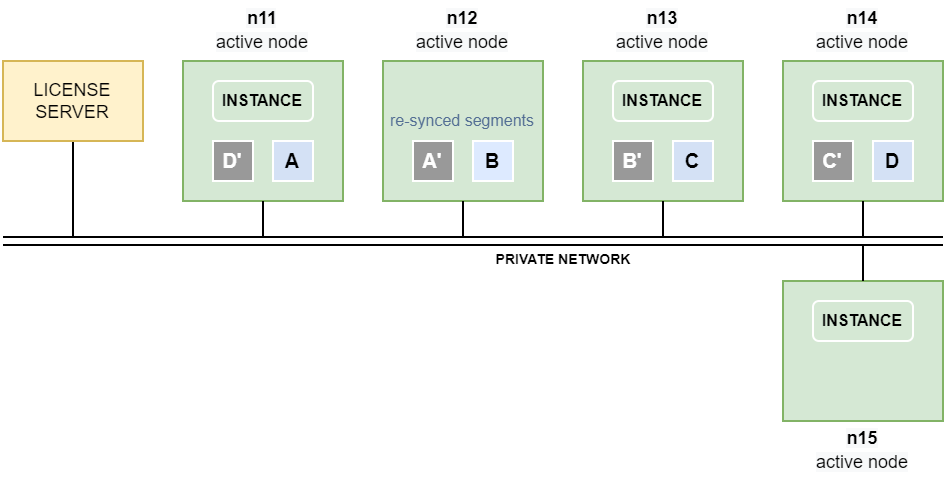
The instance on node n15 now works on the segments residing on node n12, until the database is restarted.
Restart the database
Restarting the database after a transient node failure will re-establish the initial scenario with n11–n14 as active nodes and n15 as reserve node.
Move Node
To avoid the downtime caused by restarting the database after a transient node failure, an alternative method is to use the Move Node operation, which will not cause any downtime.
In the following example the segments residing on node n12 are copied over the private network to node n15.
Moving data between nodes is time consuming and puts a significant load on the private network. If the private network has been separated into database network and storage network, copying is done through the storage network.
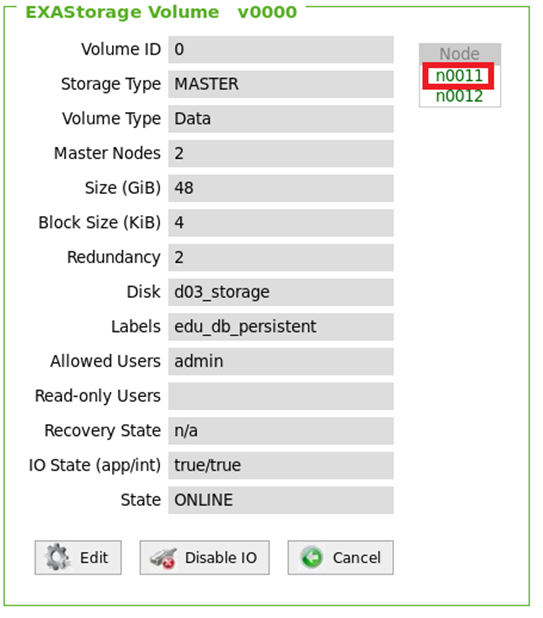
Select the affected volume and node:
Select the node presently not used for the volume:
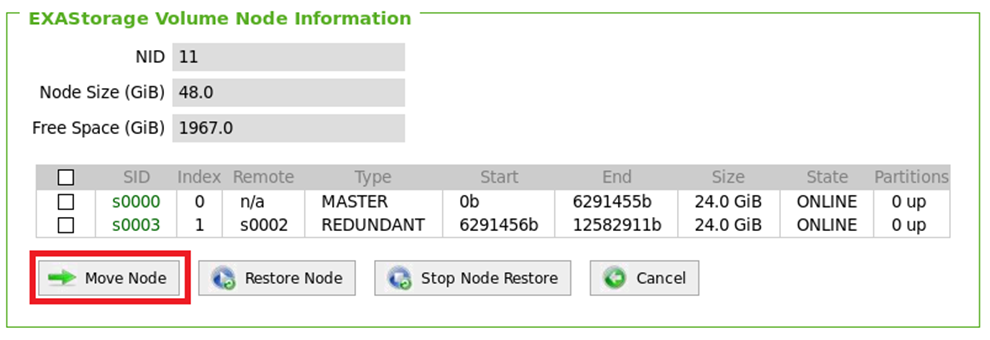
Click on Move Node.
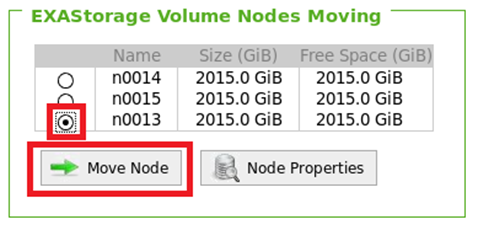
Select the target node, then click again on Move Node.
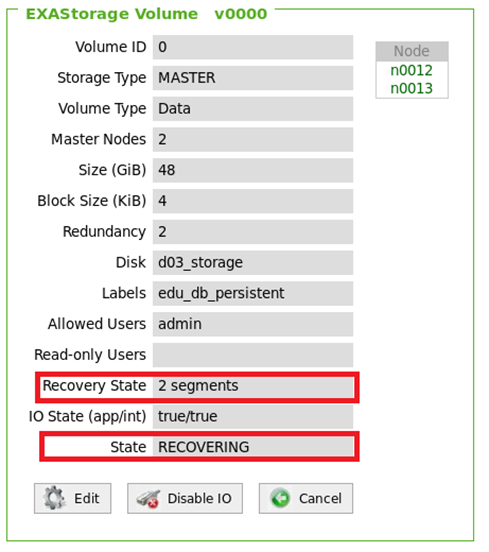
Monitor Recovery Progress
The ongoing recovery can be monitored in the volume detail page.
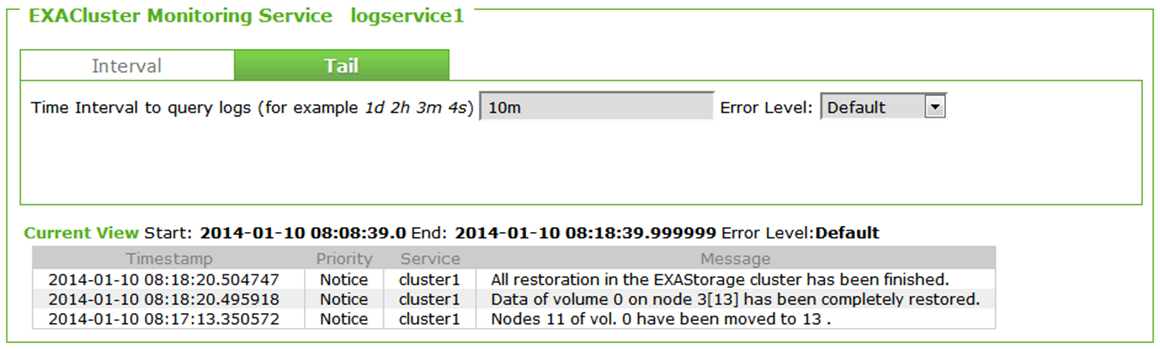
Log entries
The result of the restore process can be seen in the log maintained by the logservice.
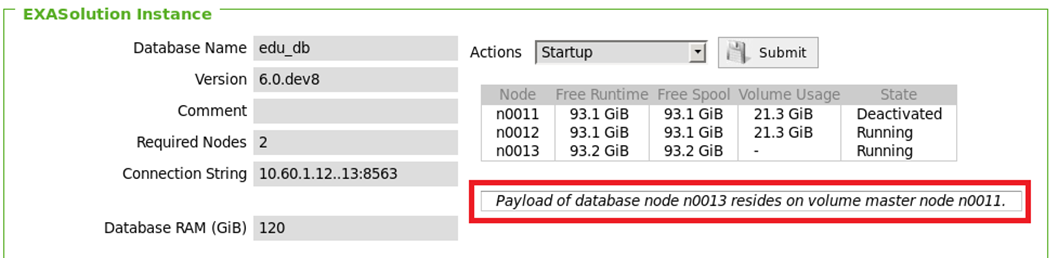
Verify where the database node payload resides
EXAoperation will indicate on which volume master node the payload of a database node resides.