Learn about some best practices to follow when loading data into Exasol.
Use ELT instead of ETL
ETL (extract, transform, load) is a commonly used method for transferring data from a source system to a database. An ETL process involves extracting the data from sources, transforming it, and then loading it into the database. However, you can often improve performance for the data transfer operation by using an ELT process (extract, load, transform) instead of ETL.
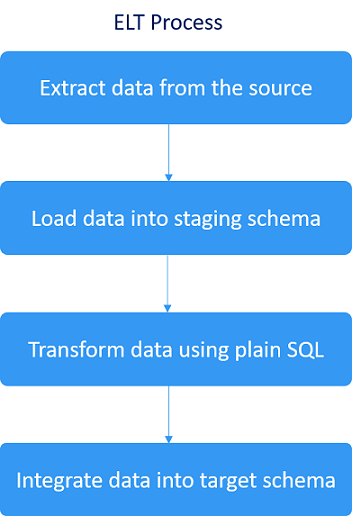
An ELT process involves extracting data from sources, loading it into a staging area in the database, transforming the data using SQL (adjusting formats, checking primary keys and foreign keys, checking data quality, normalizing data), and then integrating data into the target schema. The staging area is usually a schema within the database that buffers the data for the transformation. The transformed data is then integrated into the corresponding target schema of the same Exasol database instance.
There are several advantages of using a staging area:
- Since the transformation is done from within the database, the full cluster performance is utilized.
- Integration of data from the staging area into the target schema is fast and uncomplicated.
- There is no contamination of data in the target schema with the temporary staging data.
![]()
Data transformation
When transforming source data within Exasol, processing data as data sets is more efficient than row-based processing. When you transform data as data sets, the process is as follows:
- Identify possible error cases
- Check all rows and set error codes
- Integrate all correct rows in the target tables
- Optional – keep invalid data on the staging area for further processing
Primary key constraint check
Since Exasol does not support cursors, execute all checks on the data within the staging area, and integrate only the transformed and checked data into the target schema. For example:
Initial State:
- Fact table SALES_POSITIONS - PK (SALES_ID, POSITION_ID) - FK (SALES_ID)
– Staging table SALES_POS_UPDATE – This includes only the relevant columns.
Therefore, only the new sales positions are transferred from the staging table to target schema, leaving the erroneous entries in the staging table with an appropriate error message.
As an example for set-based approach to the above:
UPDATE STG.SALES_POS_UPDATE su
SET error_text='SALES_ID already exists'
WHERE EXISTS
(
SELECT 1 FROM RETAIL.SALES_POSITIONS s
WHERE s.SALES_ID = su.SALES_ID
)
;
INSERT INTO RETAIL.SALES_POSITIONS
(SELECT SALES_ID, POSITION_ID, ARTICLE_ID, AMOUNT,
PRICE, VOUCHER_ID, CANCELED
FROM STG.SALES_POS_UPDATE su
WHERE su.ERROR_TEXT IS NULL
);
DELETE FROM STG.SALES_POS_UPDATE
WHERE error_text IS NULL;In many cases, the staging table not only contains new entries but also updates of existing rows.
The sales positions that should be removed from the SALES_POSITIONS table might be located in the staging table too.
For this purpose, you could omit the primary key check and replace the INSERT by an appropriate MERGE statement as shown below:
MERGE INTO RETAIL.SALES_POSITIONS s
USING STG.SALES_POS_UPDATE su
ON s.SALES_ID = su.SALES_ID
AND s.POSITION_ID = su.POSITION_ID
WHEN MATCHED THEN UPDATE SET
s.VOUCHER_ID = su.VOUCHER_ID
WHEN NOT MATCHED THEN INSERT VALUES
(SALES_ID, POSITION_ID, ARTICLE_ID, AMOUNT,
PRICE, VOUCHER_ID, CANCELED)
;Data import and export
Instead of a separate bulk loading tool, Exasol provides the integrated SQL commands IMPORT and EXPORT to exchange data with many different types of systems. You can integrate data from flat files, databases, Hadoop, or any type of data source. You can also write your own connectors using ETL user defined functions (UDFs).
Use IMPORT and EXPORT to transfer data between Exasol and:
- Other Exasol databases
- Other databases through a JDBC interface
- Oracle databases, using Oracle Call Interface
- Files (CSV, FBV)
- UDF Scripts (including Hadoop)
To achieve optimal parallelization:
-
If you import from an Exasol database, importing is always parallelized. Loading tables directly will then be significantly faster than using the
STATEMENToption. -
If you import data from Oracle sources, partitioned tables will be loaded in parallel.
-
If you import data from JDBC or Oracle sources, specifying multiple
STATEMENTclauses will allow them to be executed in parallel, which may improve performance compared to loading all data as a singleSTATEMENT. You can only specify multiple statements for JDBC and Oracle sources.
Avoid small data inserts
Avoid small data inserts, especially single-row IMPORT or INSERT. Multi-row inserts are faster than multiple single-row INSERT statements.
Use IMPORT instead of INSERT
Using the IMPORT statement will result in better performance than using INSERT unless you are loading a very small amount of data (100 rows or less). When loading larger amounts of data, IMPORT is normally faster.
Use bulk insert
To enhance the performance of data insertion, use the bulk insert option. To bulk insert data, group multiple rows in a single multi-row INSERT statement. Choose the largest possible bulk size.
Transactions
Avoid multiple INSERT statements into the same table, use the bulk load option instead. Multiple INSERT statements from different sessions done simultaneously on the same tables will very likely lead to transaction conflicts. You may also receive the WAIT FOR COMMIT message and experience further delays.